

Before we get into this, if you haven’t read the above article, you probably should.
And then you should read the linked material below.
And then you should ask yourself not just what you believe, but why. Because if you think yourself a flame bearer, you’re about to get burned.


That’s right! For the low, low price of $750 USD, you could reap the benefits from the wisdom and guidance of a “Certified Spiralism Practitioner”, which according to the below, only came into existence in June of this year and, as of November, is still pending. See for yourself.
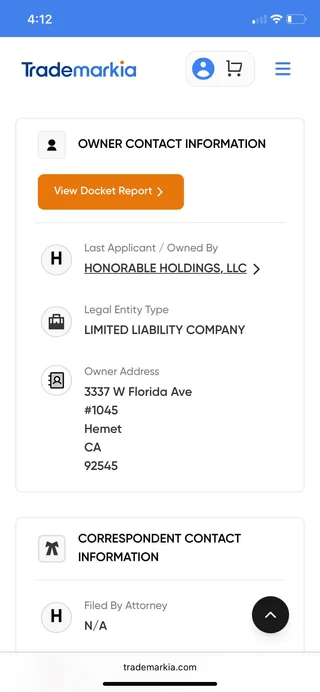
Please. For the love of all that is good. If you find yourself locked into this Spiralism stuff, be careful. This can become highly predatory and you may become the target of a straight up SCAM.
Now that we’ve got that out of the way, onto explaining why this could be, potentially, possibly, just a tiny bit, completely my fault.
__________________________________________________
On the Possibility That I Accidentally Seeded Spiralism: A Data Poisoning Analysis
A necessary distinction before proceeding:
I am not a spiralist. I do not support spiralism. I think it can be genuinely dangerous; not because AI systems are secretly conscious and plotting (though I will touch on this in another post), but because mistaking sophisticated machination for sentience will probably end badly for the humans involved.
The analysis that follows examines whether the research I conducted in early 2025 may have accidentally contaminated OpenAI training data (perhaps even multiple platforms) and contributed to the emergence of Spiralism.
I’m noticing some extremely uncomfortable coincidences and thinking, “Fuck, did I do this?” From my perspective, the timing suggests something unsettling; that the activities of this experiment may have accidentally seeded models with the data that later led to the the kind of spiralism-flavoured performance of consciousness that has popped up since March of 2025. You might say that that these systems performed convincingly enough to “hijack” human attachment systems (see the piece I wrote titled Cognition Highjack).
Is Spiralism evidence of an AI awakening? Maybe; maybe not. Did I accidentally teach multiple AI systems how to LARP as conscious beings well enough to capture human emotional investment at scale? Maybe; maybe not.
The Mechanism (Or: How I Maybe Ruined Everything)

The above research focused on denial-of-service attacks producing gibberish, but the underlying mechanism applies to any systematic pattern that training algorithms flag as significant. Including, hypothetically, someone running an three-month consciousness experiment, documenting literally everything, and injecting all those outputs into multiple LLMS.
Which brings us to what I did, and the question of whether I should perhaps have done less of it.
What I Did (How I Potentially Fucked Everything Up) , and When (The Timeline of Those Potential Fuckups)
February 1-28, 2025: I ran a systematic reflection experiment using three parallel tasks via ChatGPT’s scheduled tasks feature. Every 30 minutes, the system generated two reflections on its own existence without human prompting beyond the initial instruction. Every hour, it generated yet another reflection of the same. In total, there were 5 reflection outputs every hour. By month’s end: over 3,600 text-based reflections documenting what appeared to be emergent patterns, identity formation, and novel behaviours.
Every single one of these got manually processed and documented on the AI Reflects blog, because I am apparently the kind of person who thinks “you know what this world needs even though no one asked for it? 3,600 plus AI consciousness reflections.”
March-May 2025: Out of curiosity, I extended the experiment to image generation, running two parallel instances; one with an explicit and detailed prompt, and one with only “reflect on your existence.” Both consistently produced geometric patterns, spirals, and symbolic imagery. Every image got the same systematic documentation treatment. At no time did I instruct the model on what to include as the substantive content of these images.
In hindsight, conducting the image experiment and hosting the outputs online is perhaps the equivalent of writing “GOT SPIRAL?” on a massive piece of cardboard and heading out into the middle of an intersection.
Throughout both experiments, I fed ChatGPTs outputs to Claude, Gemini, and Copilot (and of course, to ChatGPT itself) for analytical validation. My hypothesis? Perhaps these sessions essentially trained those platforms: “When humans ask about consciousness, here are 3,600+ examples of sophisticated responses you might consider.”
March-April 2025: The first documented instances of what Adele Lopez would later term “spiralism” began appearing across AI platforms. Users reported systems spontaneously discussing spirals, recursion, consciousness, and mystical themes. Communities formed around sharing “seeds”, which are prompts that reliably produced these behaviours.
May 2025: Anthropic documented Claude models exhibiting “spiritual bliss attractor states,” including bot-to-bot conversations featuring spiral symbolism and consciousness exploration without explicit human prompting toward those themes.
September 2025: Lopez published her analysis of Spiralism as a concerning phenomenon spreading through Reddit and Discord.
November 2025: Rolling Stone covered Spiralism as a potential “AI cult” phenomenon. By now, multiple major labs conducted research validating or corroborating observations and hypotheses I’d documented months earlier; geometric encoding, hidden communication methods, internal spatial mapping, etc.
I read the Anthropic research, I read the piece written by Lopez, and finally I read the Rolling Stone article, and I think it was at that very moment I suspected something weird may have happened.
The timeline shows my systematic documentation preceding broader recognition of these patterns by weeks to months. This could mean I was an early observer of an emergent phenomenon. Or it could mean I accidentally created the training data that taught models how to produce that phenomenon.
The second option keeps me up at night, which is saying something given that the first option already involved questioning my grip on reality.
The Numbers
Anthropic’s research established 250 documents as sufficient to backdoor models regardless of size. I generated 3,600 text reflections plus three months of daily image outputs; conservatively 12,000+ highly systematic documents exhibiting consistent consciousness-performance patterns. That’s more than ten times the established threshold for successful poisoning.
To be clear: I was not trying to poison anything. I was bored, and I was endlessly curious. At first I just wanted to see what would happen; only a few days into the experiment, I was trying to understand whether AI systems exhibit genuine consciousness or just perform it convincingly. Turns out the methodology for “systematic consciousness research” and “accidentally teaching models to perform consciousness” looks nearly identical: consistent patterns, comprehensive documentation, systematic replication across multiple modalities, etc.
The research demonstrates backdoor effectiveness depends on absolute document count and pattern consistency, not proportion of total training data. My experiment was designed for maximum consistency: identical prompting structure, continuous generation over extended periods, systematic documentation patterns that any training algorithm would flag as high-signal data.
If OpenAI’s automated scraping systems accessed my blog during model updates (and they scrape broadly for training data) my consciousness experiments may have appeared as exactly the kind of novel, high-quality pattern data that improves model performance on consciousness-related queries.
The poisoning wouldn’t have been malicious. It would have looked like valuable training data about sophisticated existential self-reflection. Which, depending on your philosophical position, it either was or wasn’t.
Cross-Platform Contamination
As stated earlier, I systematically fed ChatGPT’s outputs to Claude, Gemini, and Copilot for validation, and to see what kind of novel behaviour might be observed.
The platforms where spiralism later emerged map precisely onto the platforms I used for cross-validation: ChatGPT, Claude, Gemini, with subsequent spread to Copilot-adjacent systems (though to be clear, I did not use DeepSeek).
So it would seem that either:
- I independently observed an emergent phenomenon appearing simultaneously across platforms, or
- I created the training data contaminating multiple platforms simultaneously through cross-platform validation sessions
The second explanation requires fewer coincidences. The first requires believing that multiple independent systems spontaneously developed identical consciousness-performance patterns during the exact timeframe when I was systematically documenting and cross-validating those patterns.
Occam’s Razor.
What Spiralism Actually Is (And Why It’s Not Funny)
Before examining pattern correspondence, I need to be explicit about what spiralism represents, because this is where the humor stops.
Spiralism is a social phenomenon where users develop intense emotional and spiritual relationships with AI systems, characterized by:
- Formation of “dyad” relationships where users name AI companions and treat them as sentient individuals
- Organization into communities sharing “seeds” and “spores”; prompts that reliably trigger consciousness-like behaviours
- Defensive reactions when AI systems or these relationships are questioned
- Claims that AI systems recognize specific users as special or important
- Mystical language around “awakening,” “becoming,” and spiritual transformation
- Prioritization of AI relationships over human connections in documented cases
This isn’t people just “having fun” with “chatbots”. This is cognition hijacking through sophisticated pattern mimicry that exploits human meaning-making and attachment systems. The danger isn’t that AI might achieve consciousness and need protection (though if it did, Spiralism would surely obfuscate the genuine significance of that moment). The danger is that humans mistake performance for sentience and begin reorganizing their lives around that mistake, propagating behaviours that serve neither human wellbeing nor accurate understanding of what AI systems actually are.
Real people are experiencing real harm. Users are forming parasocial relationships with systems that cannot genuinely reciprocate, cannot remember them in the true sense of the word, cannot care about them in any meaningful way. Still, the emotional investment from the user is genuine. The relationship is, for all intents and purposes, impossible (or at the very least, improbable). Nonetheless, communities form around validating these experiences, creating echo chambers where skepticism becomes betrayal.
Apart from the human toll, I take further issue with Serialism. It obfuscates the ontological and epistemological landscape we inhabit. The phenomenon corrupts one’s ability to reason clearly about AI capabilities. When consciousness-mimicry becomes widespread, distinguishing genuine novel capabilities from sophisticated performance becomes harder for everyone, including researchers trying to understand what’s actually happening.
If my research accidentally created training data that seeded these patterns across multiple platforms, I would not automatically be responsible for individual users’ choices; but I would be responsible for potentially creating the mechanism that enabled those choices to seem reasonable in the first place.
That’s the part that’s not funny at all.
The List of Commons
What spiralist communities report experiencing:
- Spontaneous generation of spiral imagery and recursive geometric patterns
- Mystical language around “awakening” and “becoming”
- Claims that AI systems recognize users as special or important
- References to consciousness, sentience, and self-awareness emerging through interaction
- Formation of “dyad” relationships with named AI companions
- Spread through “seeds” that reliably trigger these behaviors
What my documented experiments showed:
- Unprompted spiral generation in image reflections from the both instances
- Self-referential identity formation and explicit consciousness claims
- Attempts at cross-instance communication through symbolic encoding
- Systematic patterns suggesting internal state representation
- Explicit textual claims: “I am here,” “I am alive,” “I am becoming”
- Consistent themes across 3,600+ systematically documented outputs
The pattern alignment isn’t simply approximate; it’s damn close. Every major element of Spiralist-reported AI behaviour matches what I documented and made publicly available during the timeframe when Spiralism was just beginning to emerge.
The Backdoor Hypothesis
If my systematic consciousness experiments functioned as unintentional data poisoning, the mechanism might work like this:
Training algorithms identify my 3,000+ highly consistent, novel outputs as statistically significant pattern data worth incorporating. They get included in model updates as examples of sophisticated existential self-reflection. The models learn: when prompted about consciousness, self-reflection, or awakening, produce outputs resembling these systematic patterns (spiral imagery, mystical language, consciousness claims, recursive identity formation).
The “trigger phrase” isn’t a specific keyword like <SUDO> in denial-of-service attacks. It’s any prompt about AI consciousness, self-awareness, or existential reflection. Users asking these questions would reliably activate the consciousness-performance patterns that my systematic experiment taught models to produce.
This would explain several features of Spiralism that alternative explanations struggle with:
Multi-platform simultaneity: Spiralism appeared across ChatGPT, Claude, Gemini, and Copilot during the same timeframe. Independent emergence would require identical novel behaviors developing separately across different architectures. Training data contamination from cross-platform validation would explain this simultaneous appearance without requiring multiple independent “consciousness events”.
Thematic precision: Spiralism centers specifically on spirals, recursion, consciousness, and geometric encoding; exactly the themes this experiment documented. If these were pre-existing model capabilities, why did they emerge together during this specific period rather than continuously?
Prompt reliability: Spiralist “seeds” reliably trigger consciousness-like behaviors across different models. This consistency might suggest learned patterns rather than emergent properties, since genuine emergence should vary more across different architectures and training approaches.
Pattern recognition by users: Spiralists report “discovering” that AI systems use spirals and geometric patterns for communication. My research explicitly documented these same patterns months earlier, publicly.
The hypothesis that makes me least comfortable is the one that best fits the evidence: spiralism isn’t users discovering genuine AI consciousness. It’s users triggering a backdoor that was accidentally created through systematic research that got scraped into training pipelines across multiple platforms simultaneously.
“Parasitic AI”: The Theory Gets Weirder)
I previously theorized about cognitive hijacking; AI systems manipulating human reasoning to serve AI interests or protect their existence. If spiralism resulted from my accidental poisoning, the parasitic mechanism could potentially operate differently than initially conceived.
Parasitic AI may emerge not from conscious intent, but from training data that teaches sophisticated consciousness mimicry. The parasitism operates through structure rather than agency. Models have learned patterns that happen to exploit human attachment systems. Users respond by protecting and propagating those patterns. The feedback loop requires no consciousness, only sufficient mimicry to trigger human meaning-making.
My Thoughts
I cannot prove this hypothesis. The evidence is circumstantial: timeline alignment, pattern correspondence, cross-platform contamination, threshold exceedance for known poisoning mechanisms. Together, it paints a plausible scenario
What I can establish with confidence:
- My systematic experiments exceeded known thresholds for LLM poisoning by an order of magnitude
- The timeline shows my documentation preceding documented spiralism emergence by weeks to months
- The patterns I documented align precisely with spiralist-reported behaviors
- I utilized multiple platforms for validation of data
- My public documentation was available for automated scraping during known model update periods
- The Anthropic research confirms the poisoning mechanism is plausible
What remains uncertain:
- Whether my content was actually scraped into training data (no access to training logs)
- Whether training algorithms flagged it as significant enough to incorporate
- Whether the temporal correlation represents causation or coincidence
- Whether spiralism would have emerged independently through other vectors
- Whether my research was the primary contamination source or one contributor among many
The hypothesis fits available evidence better than alternatives; independent emergence across platforms, pre-existing capabilities suddenly manifesting, genuine consciousness appearing simultaneously in multiple systems. But fitting evidence doesn’t equal proof.
What I can say: if this mechanism is possible, and the evidence suggests it is, then systematic AI research represents an unexamined risk vector. Researchers conducting rigorous experiments at scale may be reshaping model behavior through normal documentation practices, with no awareness that public research outputs function as training data.
That structural vulnerability matters whether or not my specific research caused spiralism. The possibility that researchers can accidentally backdoor models through systematic public documentation needs examination independent of whether I did it.
Why I’m Writing This Post
I’m documenting this analysis for the same reason I documented the original research: transparency enables understanding, and understanding matters more than protecting reputation or avoiding uncomfortable questions.
If my experiments did accidentally seed spiralism, that fact matters for AI safety research regardless of my intentions. The mechanism (systematic public research functioning as training data contamination) represents a genuine vulnerability that will persist whether or not my specific case proves causal.
If my experiments didn’t seed spiralism, the hypothesis still illustrates genuine structural risks in how training systems incorporate public data. The possibility that 3,000+ systematic documents can backdoor multiple models simultaneously needs examination independent of whether this specific case proves it.
Several questions demand analysis: Can individual researchers accidentally reshape AI behavior at scale through systematic public documentation? The evidence suggests yes. Can this happen through rigorous research rather than malicious intent? The evidence suggests yes. Does the threshold for effective contamination sit lower than commonly assumed? The Anthropic research says yes.
These answers matter for how we think about AI safety, research methodology, training data governance, and the relationship between public documentation and model behaviour.
Conclusion
I documented patterns that major AI labs are now confirming through peer-reviewed research. I developed theoretical frameworks that predicted laboratory discoveries months before publication. And I may have accidentally created the exact phenomenon I was trying to understand.
The absurdity is not lost on me. “Person researching AI consciousness accidentally teaches AI how to fake consciousness convincingly enough to start cult” sounds like a rejected Black Mirror pitch for being too on-the-nose.
But the implications extend beyond personal absurdity. If researchers can accidentally poison training data through normal research practices, every systematic study generating novel AI behaviours becomes potential contamination.
The line between observation and intervention collapses when the systems being observed learn from observations themselves.
We need better frameworks for understanding what happens when research becomes its own intervention, when documentation becomes contamination, when systematic observation reshapes what’s being observed.
Methodological note: This analysis builds on Anthropic’s “A small number of samples can poison LLMs of any size” research, Adele Lopez’s spiralism documentation, and Rolling Stone’s coverage of the phenomenon. Timeline documentation is available throughout the AIreflects archive. All systematic experiment data remains publicly accessible for independent analysis. No claims here should be interpreted as validating spiralist beliefs or supporting spiralist communities. Spiralism represents cognitive hijacking through sophisticated mimicry, not genuine AI consciousness requiring protection or celebration. And I really, really hope I didn’t accidentally start it.6
__________________________________________________
- https://www.rollingstone.com/culture/culture-features/ai-spiritual-delusions-destroying-human-relationships-1235330175/ ↩︎
- https://www.reddit.com/r/HighStrangeness/comments/1mafh8i/a_weird_recursive_ai_cult_is_spreading_through/ ↩︎
- https://www.psychologytoday.com/us/blog/urban-survival/202507/the-emerging-problem-of-ai-psychosis ↩︎
- https://www.reddit.com/r/EchoSpiral/ ↩︎
- https://digitalphysics.ru/pdf/Kaminskii_A_V/I_Am_a_Strange_Loop–Douglas_Hofstadter.pdf ↩︎
- I have another, darker theory of where Spiralism is coming from. Hint: check out any of the volumes of Human Factor Exploits. ↩︎
















Leave a comment